
내 멋대로 구현한 이벤트 드리븐
중국 이커머스 최대 행사인 쐉쓰이(双十一)때 11월11일 0시가 되자마자 매출이 급상승함과 동시에 이벤트가 미친듯이 순식간에 몰려드는 것을 보고,
일 년 전 밤을 지새우며 O2O 시스템을 Event driven 방식으로 바꾸느라 고생했던 순간이 떠올랐다.
쐉쓰이의 분위기는 동료가 쓴 글인 개발자가 바라본 중국 쇼핑 축제 쐉쓰이(광군제)에 생생하게 나타나 있다. 실제 당일날 MongoDB 인덱스 문제, 디스크 부족으로 인한 kafka 서버 장애, 등 몇몇 문제가 발생하기도 했지만, 고객에게는 문제없이 서비스가 제공되었고1, 쐉쓰이(双十一)는 무사히 지나갔다.
이번 글에서는 쐉쓰이(双十一)를 버틸 수 있었던 요소 중 하나였던 Event driven 방식을 소개하려고 한다.
배경
작년 한 해 꽤 긴 시간 동안 Event Driven 과 씨름해왔었다. 그 배경에는 두 가지가 있었다.
1. Keeping Track of Changes in a History
매장을 운영하는 데 있어서 재고 데이터는 아주 중요하다. 물건을 하나 팔면 재고 수량을 -1 하면 되고 물건이 들어오면 재고 수량을 +1 하면 되지만, 이 간단한 말이 그렇게 간단하지가 않더라. 우리는 지금까지 단 한 번도 고객에게 실제의 재고 데이터를 보여주지 못했다.
그런데도 고객은 계속해서 재고를 맞추게 해 달라고 요구하고 있었다. 우리는 그것을 다르게 풀고 싶었다. 사실 그들이 원하는 것은 ‘그래서 재고가 몇 개야?’ 에 대한 단답형 대답이 아니라 ‘재고가 왜 이렇게 되었어?’ 에 대해 그 근거를 찾고 싶은 것이었다. 그것은 단순히 시스템을 오류 없이 정교하게 만드는 것만으로는 불가능했다. 재고의 변화 이력이 남아있고 그것이 추적 가능해야 했다.
… 그래서 Event Driven?
2. Eventual Consistency
우리가 제공하는 큰 서비스 중 하나가 O2O(Online to Offline) 서비스인데, 고객이 온라인에서 물건을 구매하면, 어딘가에 있는 오프라인 매장에서 고객에게 물건을 배송해주는 서비스이다. 알리바바가 운영하는 天猫(tmall.com)에서 주문이 발생하면, 중국 전역에 있는 수천개 매장에서 그 상황을 바로 알 수 있다. 그리고 내 매장에 물건이 있으면 그 주문을 찜하고(抢单) 내 매장에 있는 물건을 보내면 된다.
11/11은 광군제라고, 중국판 Black Friday다. 일 년 전체 매출의 절반이 이날 하루에 일어난다. 그래서 중국에서 온라인 커머스 사업을 하는 회사에 11/11은 가장 중요한 날이다. 중국에서 IT 회사를 평가하는 기준은 아주 심플하다. “너희 11월 11일 잘 넘겼어?” 이 질문에 자신 있게 대답할 수 있으면 괜찮은 회사인 거고, 그게 아니면 허접스러운 회사다. 11/11을 문제없이 잘 보냈느냐로 그 회사의 수준이 매겨지는 것이다. 그날 하루 폭주하는 주문량을 처리해내는 것이 중국에 있는 온라인 커머스 기업의 가장 큰 과제이다.
지금까지는 모든 업무가 하나의 큰 MSSQL 서버에서 수백 라인의 프로시져에 의해 one transaction으로 처리되고 있었다. 주문 건을 조회하기 위해 주문 내역과 매장 재고, 각종 정책을 매번 계산하고 있었고 抢单(배송 찜하기) 버튼 클릭 하나에 어마어마한 작업이 한 트랜잭션에 묶여서 돌아간다. 시간이 지나 데이터가 쌓여감에 따라 처리 속도는 점점 느려지고, 주문량이 조금만 늘어나도 시스템은 버벅거린다. 작은 프로모션 행사 하나에도 가슴 졸이며 DB 서버의 CPU와 메모리 그래프를 보고 있고, 그러다 (예상과 같이) 시스템은 곧 다운되어 버린다.
어떻게든 되게 하자!
이것이 중국의 여러 서비스를 사용하면서 배운 중국의 방식이었다.2 중국의 모바일 서비스에서 다른 그 어떤 것보다 우선시 되는 것이 있다면, **“고객이 한번 실행했던 기능은 반드시 처리되어야 한다”**는 것이다. 그것을 위해선 다른 것들(예쁜 UI, 깨알 같은 디테일, 등)은 좀 감수해도 허용이 되더라. 분명 위챗을 통해 온라인 송금을 했는데 10분이 지나도 상대방에게 전달이 안 되는 경우도 있고(언젠가는 된다), 모바일을 통해 가입했는데 며칠이 지나도 승인이 떨어지지 않는다(언젠가는 된다). 지금 당장은 아니더라도, 언젠가 반드시 된다는 보장만 해주면 문제없다.
이러한 생각을 우리 O2O 시스템에도 적용하기로 했다. 지금 당장 단번에 완벽하게 처리하는 것이 불가능하다면 차근차근 한 단계식 처리되도록 해서 언젠가는 되게 하자.
… 그래서 Event Driven?
삽질
이런 배경으로 Event Driven에 손을 대기 시작했다. Event Driven을 구현하기 위한 여러 개념을 학습했는데 공부를 하면 할수록 모호하기 짝이 없었다.
어렵다고 느껴졌던 이유 중 하나는 실컷 공부해 놓고도 내가 제대로 공부했는지 알 수가 없었다는 것. 다른 것들은 공부를 한 만큼 바로 코드에 적용해 볼 수 있었고 눈으로 바로바로 확인되었지만, Event Driven 책들은 하나같이 꼰대같은 말들만 하고 있더라. 힘든 영어를 꾸역꾸역 읽고 나서도, ‘그래서 어떻게 하란 말이야?‘란 생각이 먼저였다.
하나의 이름에 대한 구현방식은 너무나 제각각이었다. Event Driven에서 제안하는 다양한 방식을 직접 구현해보았다. 여러 언어들을(Go, C#, Ruby) 사용해서 데이터베이스도 바꿔가며(MongoDB, EventStore, Kafka, Mysql, RavenDB,,,) 이것저것 다 적용해보고, 우리 비즈니스를 거의 4~5가지 버전으로 만들어도 보았다. 그래도 여전히 ‘이게 맞나?‘라는 의문이 가시지 않았다.
CQRS, Event Soucing, Command, Event, Aggregation, Snapshot,,, 이런것들을 코드에 꾸역꾸역 집어 넣어가며 다 구현한 뒤 내 생각은 ‘이렇게까지 해야 해?‘였다.
내 멋대로
머릿속을 복잡하게 하는 것들은 싹 다 버리고, 위키피디아에 나오는 설명 중에서 눈에 들어오는 몇 가지 단어(event emitters, event consumers, event channels)만 뽑아서 그것을 중심으로 설계를 해 보았다.3
사용자 요청을 중심으로 움직이던 시스템을 이벤트에 의해 흘러가도록 설계를 변경하였다. 비즈니스적으로 중요한 사건과 행위를 도출하여 그것을 화이트보드에 옮겨보았다. 왼쪽 아래로 써 내려간 것이 이벤트(Event)였고, 오른쪽 옆으로 나열한 것이 처리해야 할 행위(Command)였다.
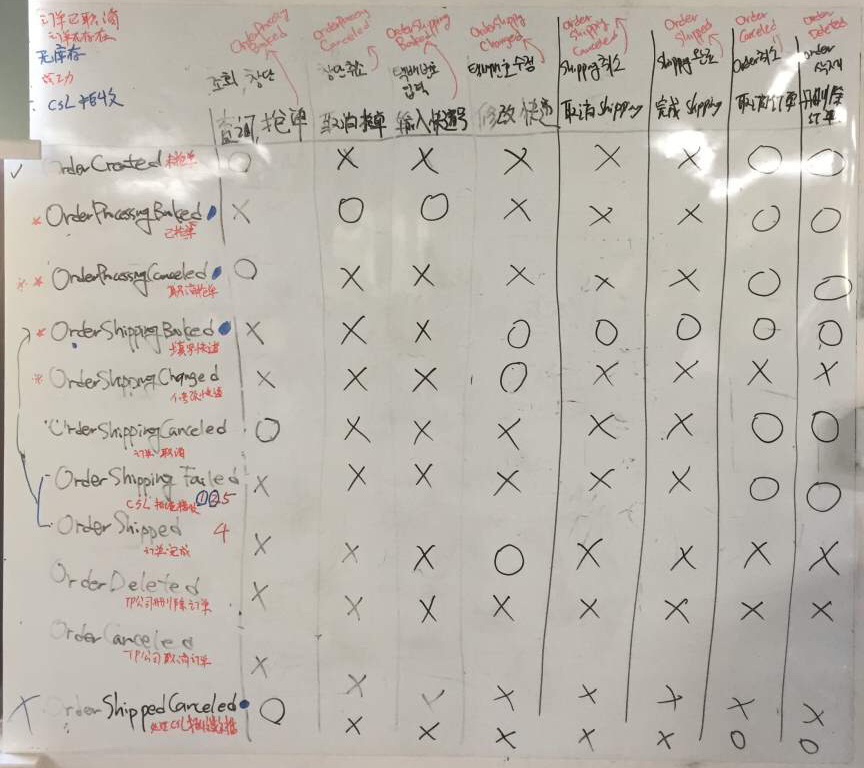
우리 중 몇몇은 이것을 “지도"라고 불렀다. 개발을 하다가 모호한 상황이 발생하면 모두 저 화이트보드 앞으로 모여 지도를 다시 그렸다. 회의를 하다가도 화이트보드 앞으로 다가가기 일쑤였다.
O2O에는 8개의 마이크로서비스가 있는데, 각 마이크로서비스는 내 서비스와 연관이 있는 Event를 받아서 내 서비스에 맞게 데이터를 가공하여 저장해놓고, 어떤 처리가 끝나면 다음 Event를 발생시키면 끝이었다. 꼬리에 꼬리를 물고 이어졌던 로직은 우리가 정의한 Event를 중심으로 나누어졌고, 한 Event에서 다음 Event 사이에 처리되어야 하는 일들만 구현하면 되었기에 소스 코드는 간소해졌다. 이렇게 각 서비스는 Event를 중심으로 서로 얽혀서 돌아가게 되었다.
Event Broker
Event Driven 방식의 시스템에서 가장 중요한 점은 이벤트는 반드시 전달되어야 한다는 것이다. 이벤트 처리 과정 중 특정 서비스에 장애가 발생하더라도, 또는 엄청난 트래픽에 시스템이 버벅거리고 있다 하더라도 Event는 반드시 전달되어야 한다.
유명한 Queue 도구(예: RabbitMQ, Kafka, etc.)를 사용하면, 도구마다 약간의 차이점은 있지만 큐 자체가 이것을 보장해 준다.4 우리는 우리의 상황을 고려하여 kafka를 선택했다. 여러 큐 중에서 kafka를 선택한 이유는 아래와 같다.
- 한번 발생한 Event는 보존되어야 한다. (kafka를 제외한 다른 대부분의 큐는 consumer에게 이미 전달한 메세지는 보관하지 않는다)
- consumer가 능동적으로 Event를 가져갈 수 있어야 한다. (kafka를 제외한 다른 대부분의 큐의 consumer는 수동적이다. 만약 Event를 전달할 그 시점에 consume 가능한 상태가 아니면 유실이 발생할 수 있다.)
각 마이크로서비스가 kafka를 바로 사용해도 되지만 우리는 중간에 이벤트를 전달하는 역할을 담당하는 Event Broker란 녀석을 두었다. 그 이유는,
- produce/consume 코드 작성은 어렵다.
‘이게 뭐가 어려워?’ 라고 생각하는 사람이 많을 텐데, 이때만 하더라도 우리 개발팀의 수준은아주 낮았다그리 높지 않았다.5 게다가 그때 당시엔 큐 도구로 어떤 것이 적합한지 확신이 서지 않았었다. RabitMQ, Kafka, NSQ, NATS등 여러 큐를 사용하며 비교해 보았지만6 여전히 확신이 서지 않았다. 여차하면 다른 큐로 교체할 수 있어야 하는데 그러면 모든 produce, consume 코드를 수정해야 했다. 그래서 각 마이크로서비스는 WEB API만 만들고 Event Broker가 WEB API 호출하여 이벤트를 전달해주는 방식을 취했다. - Retry
Consume 서비스의 문제로 이벤트 전달이 실패할 수도 있다. 일시적인 문제로 event를 처리하지 못했다면 retry를 해서 이벤트를 다시 전달해 주어야 한다. 그렇다고 모든 경우에 똑같은 retry 규칙을 적용할 순 없다. 순간적인 네트워크 문제로 실패한 경우는 2~3번 재시도 만에 성공이 되지만, DB timeout 같은 에러를 똑같은 방식으로 retry 해버리면 꽤 긴 시간 동안 다른 이벤트를 처리하지 못한다. 즉 retry도 상황에 맞게 rule을 정의하고 그 rule에 따라 처리해야 한다. - 트레이스
Event Driven 방식의 시스템에서는 이벤트의 처리 상황이 가장 중요한 정보이다. 단순히 큐의 pub/sub 상황뿐만 아니라 이벤트에 의해 비즈니스가 흘러가는 상황을 정확하게 진단하기 위해서는 트레이스 정보를 상세하게 남겨야 한다. 특히 이벤트 처리에 대한 에러는 한곳에 모여있는 게 이후 이벤트의 전달 상황을 확인하고 조치하기 편리하다. - offset 관리
개발 당시에는 kafka가 exactly once 방식을 지원하지 않았기 때문에7 자체적으로 exactly once를 보장해야 했다. 각 consume 서비스들에게 이벤트가 정확히 한 번씩만 전달되도록 하기 위해 각 consume 서비스들에 전달한 최종 offset을 관리하여 Event가 여러 번 전달되지 않도록 했다. - consume 서비스들 간 balance 조정
어떤 이벤트는 모든 consume 서비스들이 같은 속도로 처리해야 하는 경우가 있다. A,B 두 개의 서비스가 같은 event를 받아서 처리하는데, A 서비스가 아직 첫 번째 이벤트 처리를 완료하지 않았는데 B 서비스가 세 번째 이벤트를 처리해버리면 데이터의 정합성이 깨지는 경우가 있다. 이런 경우 Event broker가 consume 서비스들의 처리 속도를 맞춰준다. - partition 분산
이벤트 종류에 따라 집중되는 시간대가 다르다. 지난 11/11 상황에서는 0시부터 3시 사이에는 TMALL에서 발생한 고객의 구매 이벤트가 집중적으로 들어왔고 직원들이 출근하는 시간 즈음에는 抢单(배송 찜하기) 이벤트가 몰리다가 그 후로 택배를 발송하는 행위들이 이어졌다. 마이크로서비스의 처리 상황을 고려해서 적절하게 분배를 해 주어야 한다. 즉, 단순히 특정 partition에 subscription을 등록하고 event가 들어오길 기다리는 간단한 로직으로는 이벤트를 효율적으로 처리할 수 없다.
이런 이유로, 우리는 Event broker를 중심에 두었다.
효과
이러한 방식의 Event driven 도입으로 시스템은 더욱 유연하고 견고해졌다.
- 하나의 마이크로서비스에 문제가 발생한다 할지라도 그것이 전체의 장애로 이어지지 않는다. 단지 지연이 일어날 뿐이다. (서비스 운영자의 심적 부담 측면에서, ‘장애’와 ‘지연’은 엄청난 차이가 있다)
- 이벤트를 처리하는 로직이 추가된 경우, Event broker에 그 이벤트를 처리하는 새로운 consume 서비스를 추가로 연결하기만 하면 되기 때문에 비즈니스의 확장도 쉽다.
- 설령 DB가 날라간다 하더라도 이벤트만 보존되어 있다면, 이벤트를 기반으로 데이터의 복원이 가능하다.8
하지만 단점도 있다. 비즈니스의 흐름이 여러 이벤트로 나뉘어 있기 때문에, 문제가 발생했을 때 추적하기가 어렵다. 특히나 Event broker의 존재는 문제의 원인을 파악하는 것을 더욱 어렵게 만든다. 우리도 초창기에는 이런 어려움이 많았었다. 지금은 단계마다 상세한 트레이스 로그를 남겨 이벤트 처리 상황을 정확하게 확인할 수 있도록 했다. 트레이스 로그를 남기는 방법에 대해서는 이전 글을 참고하기 바란다.
마무리
우리는 중국 최대 이커머스 행사인 쐉쓰이를 대비해서 이렇게 시스템을 진화시켜 나갔다. 쐉쓰이가 아니었다면 이런 아키텍처를 고민했을까? 우리 뿐만 아니라 중국에 많은 서비스들이 쐉쓰이를 위해 시스템의 수준을 높이고 있다. 해마다 쐉쓰이를 보내면서, 중국 전체의 IT 기술이 다 같이 성장하는 것을 보고 있다. 알리바바나 텐센트 같은 큰 기업들은 플랫폼을 제공함으로써 모두가 함께 사용할 수 있는 환경을 조성하고, 그 위에서 크고 작은 많은 기업이 상생하고 있다. 그리고 이들은 다 같이 성장하고 있다.
주석
-
아래 그래프는 이벤트의 produce/consume 처리 개수를 분 단위로 보여주고 있다.
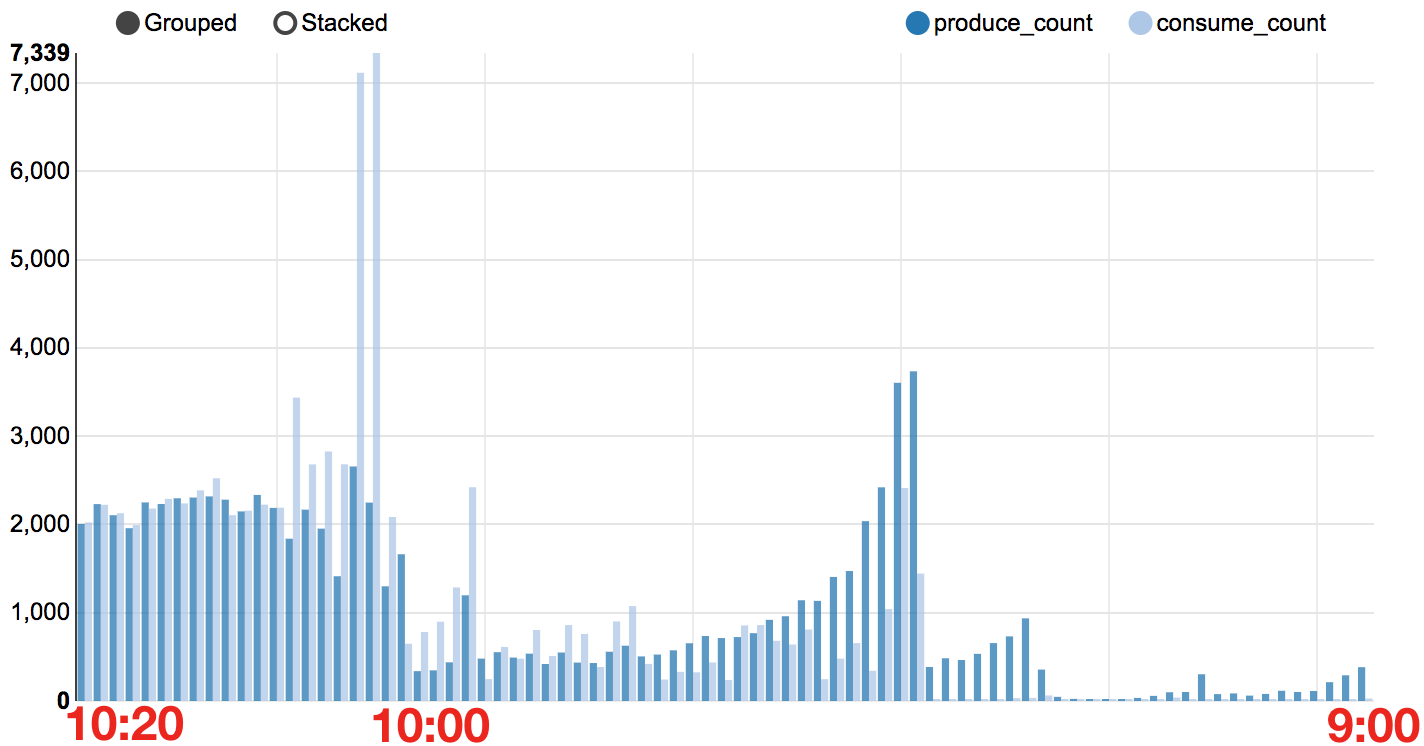 consume 서비스의 문제로 이벤트 처리가 늦어지고 있지만, 결국 모든 이벤트를 문제없이 처리하고 있음을 볼 수 있다. (위와 같이 실제 상황을 정확하게 확인할 수 있었던 것은 지난 글에서 소개한 트레이싱의 효과가 컸다.) ↩︎
consume 서비스의 문제로 이벤트 처리가 늦어지고 있지만, 결국 모든 이벤트를 문제없이 처리하고 있음을 볼 수 있다. (위와 같이 실제 상황을 정확하게 확인할 수 있었던 것은 지난 글에서 소개한 트레이싱의 효과가 컸다.) ↩︎ -
중국의 모바일 서비스에 대해서는 중국 모바일 서비스에 빠지다에 잘 소개되어 있다. ↩︎
-
이것은 함께 일하는 안영회님을 흉내낸 방식이다. 코딩하다가 문제가 잘 안 풀릴 때면 위키피디아를 펴놓고 잘 읽히지도 않는 영어를 쳐다보곤 한다. ↩︎
-
Event Driven과 단순히 큐를 사용하는 것과의 차이점은? Event Driven은 시스템이 이벤트의 흐름에 의해 동작하도록 하는 설계방식이라면 큐를 사용한 pub/sub 방식은 Event Driven을 구현할 때 사용되는 한 가지 도구일 뿐이다. Event Driven이 아니더라도 큐의 쓰임새는 아주 다양하고, 큐를 사용하지 않고 전통적인 RDB로도 Event Driven을 구현할 수도 있다. (물론 이벤트를 전달할 때 큐를 사용하는 것이 효율적일 수 있지만, 절대적으로 좋은 아키텍처/나쁜 아키텍처는 없다고 생각한다. 서비스마다 처한 환경은 다 다르고, 각자 자신의 서비스가 처한 상황에 맞게 가장 합리적인 기술 구조를 선택하는 것이 좋은 아키텍처라 생각한다.) ↩︎
-
우리 개발팀의 수준에 대해서는 동료가 작성한 글인 Micro Service, Docker로 할 수 밖에 없었던 사연을 참고하길 바란다. ↩︎
-
https://github.com/jaehue/anyq 를 보면 여러 큐를 사용하려고 시도했던 흔적을 볼 수 있다. ↩︎
-
개발 당시 최종 버전이었던 v0.10.1.0는 at-most-once/at-least-once 두 가지 형태로만 사용할 수 있었다. v0.11.0.0 이후 버전부터는 exactly once를 보장해준다 ↩︎
-
사실 우리 서비스도 이정도 수준의 복원력은 갖추고 있지 않다. 하지만, 필요하다면 kafka에 저장된 이벤트를 기반으로 데이터를 복원하는 것은 어렵지않게 구현할 수 있다. 데이터 복원을 위해 이벤트를 보존하려면 kafka의 log retention(디스크에 메시지를 얼마나 오랫동안 유지할지에 대한 설정)을 적절하게 셋팅해주어야 한다. ↩︎