Go로 안정적인(resilient) 서비스 만들기 — panic·recover, 타임아웃, pprof
http://blog.remotty.com에 게시한 글을 Go 언어에 대해 발행한 글을 수집하는 차원에서 이곳으로 옮겨왔다.
서비스를 만들때 비정상적으로 서비스가 종료되지 않고 안전하게 실행되도록 하는 것은 아주 중요하다(Resilency). 이번 포스트에서는 Resilency를 유지하면서 서비스를 작성하는 여러가지 방법에 대해서 소개하겠다. 오늘 소개하는 글은 지난 7월에 덴버에서 열린 GopherCon 2015에서 Blake Caldwell라는 사람이 발표한 내용을 기반으로 몇가지 설명을 곁들여서 작성한 것이다. (https://sourcegraph.com/blog/live/gophercon2015/123664481750)
사실 어떤 사람들에게는 쉬운 내용일 수 있다. 당연한 얘기를 하는 것일수도 있고… 하지만 기본을 탄탄히 하자는 의미에서, 그리고 지난 7월 덴버에서 열린 GopherCon 2015에서도 발표되었던 내용이니 한번 읽어보면 좋을 것 같다.
1. Careful Coding
1.1. Error Handling & Clean-up
에러 처리와 클린업은 Go 프로그램 작성의 기본이라 할 수 있다. 아래 코드를 보자.
resourceA, err := OpenResourceA()
if err != nil {
return nil, err
}
defer resourceA.Close()
// ...Go 프로그램에서 자주 등장하는 패턴의 코드이다.
OpenResourceA() 함수를 통해 사용할 리소스를 생성하고, 에러 처리를 한 후
리소스 사용이 끝나면 Close() 메쏘드를 통해 클린업 작업을 한다.
자. 여기서 OpenResourceA() 함수의 처리 결과값인 resourceA가 nil 이라면..?
충분히 그럴 수 있다.
resourceA가 nil이 될 가능성은 여러가지가 있을 수 있다.
- 리소스를 오픈한 후에 이후 로직에서 리소스를 사용하면서 그 리소스가
nil이 된 경우 - 여러 리소스가 중첩된 상태로 사용하면서, 다른 리소스 클린업 과정 중에 함께 클린업이 된 경우
OpenResourceA()함수에서 에러가 발생하지 않았지만 처리 결과가nil이 된 경우
resourceA가 nil일때 resourceA의 Close() 메쏘드를 호출하면 panic이 발생하게 된다.
그래서 이 간단한 코드는, 사실 굉장히 주의해야 할 코드이다.
하나의 솔루션으로 아래와 같은 방법이 있을 수 있다.
// can return nil, and that's not an error!
resourceA, err := OpenResourceA()
if err != nil {
return nil, err
}
defer func(){
if resourceA != nil {
resourceA.Close()
}
}()defer 구문 안에서 resourceA에 대한 nil 체크를 하는 것이다.
하지만 뭔가 만족스럽진 않다.
10점 만점에 한 4점 정도..?
OpenResourceA() 함수를 통해 resourceA 리소스를 생성하고 해제할 때 마다 nil 체크를 하면 불필요한 코드가 계속 중복이 된다.
다른 방법은,
defer 구문으로 사용되는 메쏘드를 nil-safe하게 만드는 것이다.
// Don't forget: resource might be nil!
func (resource *Resource) Close() {
if resource != nil {
// ... clean up
}
}어떤 리소스를 close 하는 메쏘드에서 해당 리소스가 nil이라 해도 안전하게 close하도록 메쏘드를 작성해놓으면
그것을 사용하는 쪽에서는 그냥 믿고 쓸 수 있을 것이다.
다시 처음의 코드와 같아 졌다.
// can return nil, and that's not an error!
resourceA, err := OpenResourceA()
if err != nil {
return nil, err
}
defer resourceA.Close() // will never panic!하지만 resourceA는 nil-safe한 메쏘드이기 때문에
resourceA가 nil인지 아닌지 신경쓸 필요 없이 안전하게 사용할 수 있다.
사실 기본 라이브러리나 이미 잘 만들어진 외부 패키지는 그냥 믿고 쓰면 된다. 다들 잘 만들었을테니까(잉…? 이런 무책임한… ;;;;) 하지만 직접 이러한 코드를 만들어야 할 때도 있다. 예를들면 rabbitmq나 kafka 같은 다양한 큐를 같은 방식으로 사용하기 위해 큐에 접근하는 코드를 추상화 시켜 wrapping해서 사용 한다던가, 경우에 따라선 로컬 파일 기반으로 나만의 DB를 만들어 사용해야 할 때도 있다. 그러한 경우에는 리소스를 생성하고 클린업하는 코드를 직접 만들어야 하는데 그럴때 이점을 주의해야 한다.
1.2. Channels
아마 fmt 패키지가 사용되지 않는 Go 프로그램은 있어도,
고루틴과 채널이 사용되지 않는 Go 프로그램은 없지 않을까 싶다(머 있을수도 있고…;;).
그만큼 고루틴과 채널의 동작 방식을 제대로 이해하고 바르게 사용하는 것은 Go 프로그램에서 절대적으로 중요하다
아래는 지난 1월 Go 밋업에서 한국에 방문해서 좋은 발표까지 해 주셨던 Dave Cheney 블로그에 올라와 있는 글에서 따온 것이다. 채널의 가장 기본적인 속성이라 할 수 있다.
출처: http://dave.cheney.net/2014/03/19/channel-axioms
- A send to a nil channel blocks forever nil 채널에 값을 전달하면 영원히 블럭된다.
- A receive from a nil channel blocks forever nil 채널로부터 값을 받으려고 하면 영원히 블럭된다.
- A send to a closed channel panics close된 채널이 값을 보내면 panic이 발생한다.
- A receive from a closed channel returns the zero value immediately close된 채널로 값을 받으려고 하면 즉시 zero value가 리턴된다.
Go의 기본 문법을 공부했다면 누구나 아는 내용이다. 하지만 사실 이런 실수를 종종 하기도 한다. 채널을 사용할때 한번씩 더 생각해 보자.
- 내가 사용하려고 하는 이 시점에, 이 채널이 nil이 될 가능성은 없는가?
- 내가 사용하려고 하는 이 시점에, 이 채널이 close 상태가 될 가능성은 없는가?
여러 고루틴이 concurrent하게 동작하는 상황에서는 신중하게 코드를 작성하지 않으면, 다른 곳에서 아직 사용중인 채널을 close 해 버릴 수 있다.
여러 고루틴을 파이프라인 형태로 연결하는 방식은 자주 소개되는 패턴이다. 각 고루틴은 채널을 통해 파이프라인 형태로 연결이 되어, 하나의 고루틴의 아웃풋이 다른 고루틴의 인풋이 되는 형태로 이어진다. 파이프라인 패턴에서 각 고루틴을 연결시키는 채널을 닫을때 파이프라인의 시작 부분에 있는 고루틴에서부터 처리를 완전히 마친후에 채널을 닫고, 그것이 완전히 닫히면 다음 고루틴에서 모든 처리가 완료된 후에 채널을 닫고,, 이런 식으로 차례차례 채널을 close 해야 한다. 만약 채널들을 그냥 한번에 쭉 close해 버리면 파이프라인 중간의 고루틴에서 아직 처리중인 데이터를 이미 close된 채널로 전달하려고 할 테고, 그러면 panic이 발생할 수 있다. 그래서 이 당연하고 기본적인 원칙을 늘 생각하면서 이 원칙을 깨는 상황이 발생하진 않을지 생각하면서 채널을 사용해야 한다.
1.3. Panics
다음으로 강조하는 것은 panic에 대한 처리이다.
프로그램을 수행하다 보면 예상하지 못한 상황이 발생할 수 있다. 예를들면 존재하지 않는 파일에 접근한다던가 배열의 범위를 넘어서는 인덱스에 접근하려고 할때 에러가 발생한다.
Go에서는 실행중에 에러가 발생하면(예: 배열의 범위를 넘어서는 인덱스로 접근, type assertion 실패 등), Go 런타임은 panic 을 발생시킨다.
아래는 panic을 발생시키는 간단한 예제 코드이다.
package main
import "fmt"
func main() {
fmt.Println(divide(1, 0))
}
func divide(a, b int) int {
return a / b
}함수 내에서 panic 이 발생하면 현재 함수의 실행을 즉시 종료하고
모든 defer 구문을 실행한 후 자신을 호출한 함수로 panic 에 대한 제어권을 넘긴다.
이러한 작업은 함수 호출 스택의 상위 레벨로 올라가면서 계속 이어지고,
프로그램 스택의 최상단(main 함수)에서 프로그램을 종료하고 에러상황을 출력한다.
이러한 작업을 panicking이라 한다
기본 라이브러리에서 panic 을 발생시키는 함수/메쏘드
기본 라이브러리에는 “Must”로 시작하는 많은 함수가 있다(
regexp.MustCompile,template.Must). 이 함수에서는 에러가 발생하면panic()을 수행한다.
Go에는 try-catch-finally 같은 예외 처리 매커니즘이 없다.
대신 recover 함수를 사용하면 panicking 작업으로부터 프로그램의 제어권을 다시 얻어, 종료 절차를 중지시키고 계속해서 프로그램을 이어갈 수 있다.
recover()는 반드시 defer 안에서 사용해야 한다.
defer 구문 안에서 recover()를 호출하면 panic 내부의 상황을 error 값으로 복원할 수 있다.
recover()로 panic 을 복원한 후에는 panicking 상황은 종료되고 함수의 리턴값에 대한 zero-value가 리턴된다.
func main() {
fmt.Println("result: ", divide(1, 0))
}
func divide(a, b int) int {
defer func() {
if err := recover(); err != nil {
fmt.Println(err)
}
}()
return a / b
}이것은 Java나 .Net의 try~catch 블럭과 유사하다.
아래 protect() 함수는 파라미터로 받은 함수 g를 호출한다.
만약 g에서 panic이 발생하면 panic으로부터 error 정보를 가져와 화면에 출력한다.
func protect(g func()) {
defer func() {
log.Println("done")
if err := recover(); err != nil {
log.Printf("run time panic: %v", err)
}
}()
log.Println("start")
g()
}func main() {
protect(func() {
fmt.Println(divide(4, 0))
})
}
func divide(a, b int) int {
return a / b
}결과
start
done
run time panic: runtime error: integer divide by zero위와 같이 protect() 함수에 코드블럭을 클로저로 만들어 넘기면 예상치 못한 panic에 의해 프로그램이 비정상적으로 종료되는 것을 막을 수 있다.
아래는 panic, defer, recover를 사용한 예제다.
package main
import "fmt"
func badCall() {
panic("bad end")
}
func test() {
defer func() {
if e := recover(); e != nil {
fmt.Printf("Panicking %s\r\n", e)
}
}()
badCall()
fmt.Printf("After bad call\r\n")
}
func main() {
fmt.Printf("Calling test\r\n")
test()
fmt.Printf("Test completed\r\n")
}Calling test
Panicking bad end
Test completedJava나 .Net의 trycatchfinally 블럭과 유사한 효과를 준다.
defer-panic-recover 패턴은 패키지 내부의 panic을 외부에서 recover해서 명시적인 에러값을 리턴할 수 있도록 해 준다.
1.4. Avoid Race Conditions
Go 언어를 설계할 때 특별히 중점을 둔 부분이 바로 concurrency 처리이다. Concurrency 처리를 위한 Go의 방식은 메모리를 공유하는 것이 아니라 메세지를 전달하는 방식으로 동기화 하는 것이다. Go에서는 동시에 처리되어야 하는 작업을 고루틴(goroutine)으로 실행시키고 고루틴 간에 메세지를 주고 받기 위한 통로로 채널(channel)을 제공한다. 고루틴은 정보를 공유하는 방식이 아니라 서로 메세지를 주고 받는 방식으로 동작하기 때문에 Lock을 통해 공유메모리를 관리할 필요가 없어지게 되고 구현 난이도도 낮아진다.
하지만, mutex나 lock 같은 저수준의 기능을 사용하지 않고 채널을 사용한다 하더라도 deadlock의 위험은 여전히 남아있다. 예를들면 서로 데이터를 주고받는 고루틴이 있다고 가정해보자. 고루틴#1은 고루틴#2로부터 데이터를 받고 처리한 후에 결과를 고루틴#2로 보내고, 고루틴#2도 데이터를 받아 처리한 다음 다시 고루틴#1로 전달하는 상황일때, 두개의 고루틴은 deadlock에 빠질 수 있다.
Go’s Race Detector
교착상태(deadlock)와 경쟁상태(race condition)를 테스트 하기 위해 Go는 Race Detector를 제공한다.
-race 플래그와 함께 Go 프로그램을 실행시키면 deadlock이나 race condition이 발생할 가능성이 있는 코드를 찾아서 레포팅 해 준다.
다른 언어에서 concurrency 처리를 할 때, 이러한 도구가 없어서 매우 불편했다. 내가 테스트 할 때는 아무 문제가 없었지만, 운영 상황에서는 꼭 이런 1/1000의 확률을 뚫고 그 상황이 발생하더라… Go의 Race Detector는 사용하기도 아주 쉽다.
Go의 Race Detector는 동기화를 보장하기 위한 어떤 장치(예: 채널, Lock, 등) 없이 여러 고루틴이 같은 변수에 접근 하게 되어 race condition 상황이 발생한다던가, 2개 이상의 고루틴이 서로 어떠한 상황을 기다리는 deadlock이 발생할 가능성이 있는 코드를 찾아서 레포트 해 준다. deadlock이나 race condition이 발생했을때의 full stack trace를 보여주므로, trace 정보를 바탕으로 코드를 안전하게 수정하면 된다. Race Detector는 유닛테스트 뿐만 아니라 개발환경나 테스트 환경에서도 사용된다.
- Reports when variable access is not synchronized 변수의 접근이 synchronized 되지 않았을때 report 함
- Crashes with a full stack trace, including the read and write goroutines read, write 고루틴을 포함해서 전체 stack trace 정보를 보여주면서 crash
- Should be used in unit tests, development, and testing environments 유닛 테스트 뿐만 아니라 개발, 테스트 환경에서도 사용된다.
아래는 race condition이 발생할 수 있는 코드이다.
아래 코드는 두개의 고루틴이 m 맵의 첫번째 위치에 동시에 접근할 위험이 있다.
func main() {
c := make(chan bool)
m := make(map[string]string)
go func() {
m["1"] = "a" // First conflicting access.
c <- true
}()
m["2"] = "b" // Second conflicting access.
<-c
for k, v := range m {
fmt.Println(k, v)
}
}Race Detector Output
아래는 Race detector의 아웃풋이다.
$ go run -race race.go
==================
WARNING: DATA RACE
Write by goroutine 5:
runtime.mapassign1()
/usr/local/go/src/runtime/hashmap.go:383 +0x0
main.func·001()
/Users/jaehuejang/Documents/workspace/go/src/github.com/jaehue/go-talk/gophercon-korea-2015/race.go:9 +0xa3
Previous write by main goroutine:
runtime.mapassign1()
/usr/local/go/src/runtime/hashmap.go:383 +0x0
main.main()
/Users/jaehuejang/Documents/workspace/go/src/github.com/jaehue/go-talk/gophercon-korea-2015/race.go:12 +0x22e
Goroutine 5 (running) created at:
main.main()
/Users/jaehuejang/Documents/workspace/go/src/github.com/jaehue/go-talk/gophercon-korea-2015/race.go:11 +0x1ac
==================
2 b
1 a
Found 1 data race(s)
exit status 66race.go 파일의 9번째 라인과 12번째 라인이 서로 race condition 상황을 만들어내고 있고, 이 두 코드는 hashmap.go에서 crash를 일으키게 된다.
Enable Race Detection
테스트 수행, Go 코드 실행, build, install 명령을 수행할 때 -race 옵션을 주면 Race detector가 동작한다.
$ go test -race mypkg // to test the package
$ go run -race mysrc.go // to run the source file
$ go build -race mycmd // to build the command
$ go install -race mypkg // to install the package1.5. Implement Timeouts
타임아웃이 발생하는 경우는 많다.
Network Timeouts
가장 많은 상황은 network timeout이다.
- network dial timeout 네트워크 상에서 연결을 처음 맺을때 예를 들어 port는 살아 있지만 어떠한 이유로 인해 응답을 주지 않는 경우가 있다. 리소스를 만들다가 hang이 걸리는 경우도 있다. 그런 경우는 타임아웃을 걸어 다른 조치를 취하도록 해야 한다.
- network connection inactivity timeout network connection이 일정 시간 동안 inactive 상태인 경우 connection을 맺은 상태로 두지말고, 우선 끊고 다시 연결하거나 connection pool로 connection을 관리해서 다른 일을 처리하는데 사용
- total connection timeout 전체 connection 시간이 일정 시간을 넘어 선 경우 정상적으로 처리 중이지만, client의 상황이 일정 시간을 넘어서면 가치가 없는 경우가 있다. 예를들어 지금 접속자가 몇명인지를 체크해야 하는데, 실제로 그것을 처리하는 어떤 과정이 오래 걸린다면, 그냥 안보여주는 것도 방법이다.
TEST ALL THE THINGS!!!
모든 것을 테스트 하라 TDD로 개발하는 것은 어려울 수 있다. 때론 TDD가 거추장스러울 수 있다. 작년 TDD에 대한 재미난 일이 있었다. RoR 을 만든 DHH가 ‘TDD는 죽었다’라는 글로 이슈를 제기했고, 이 문제에 대해 켄트백이랑 마틴파울러가 5번의 행아웃에 걸쳐 토론을 한 적이 있다. 그때 TDD에 대해 여러 얘기들이 오고갔었지만, 모두의 공통된 의견은 Self Test는 중요하다는 것이었다. 반드시 해야 하는… 그것에 대해 반론을 제기하는 사람은 본 적 없다. Test code를 작성하는 습관을 들이자
2. Know Your Service
의외로 나의 서비스가 어떤 상태인지 모르는 상태에서 운영을 하는 사람들이 많이 있다. 사용자가 몰리거나 처리해야 할 일이 많아지면 CPU와 Memory를 많이 사용하면서 바쁘게 돌아 갈 때가 있다. 하지만, 때론 전혀 바쁠 필요가 없는 상황인데도 서비스만 혼자 엄청 바쁘게 일을 하는 경우가 있다. 그리고 그것은 결정적일때 장애로 이어진다.
대부분의 서비스는 시스템에 부하를 주지 않고 적절한 리소스를 사용하면서 안정적으로 운영되고 있을 것이다. 그러한 서비스도 사용자가 많아지게 되면서 금방 포화상태가 되고, 이러한 상황에 빠르게 대응하지 못하면 장애로 이어진다. ‘우리 서비스는 사람들이 많이 사용하지 않을꺼야’라는 생각으로 서비스를 운영하는 사람은 없을 것이다. 많은 사람이 사용하길 원할테고, 그것을 목표로 해서 서비스를 만들었다면 당연히 그런 상황이 나도 모르는 사이에 내게 닥칠 것이란 것을 대비해야 한다.
그래서 내 서비스의 상태가 어떠한지를 아는 것은 중요하다. 그리고 그것을 빠르게 확인하기 위한 준비를 해 두어야 한다.
효과적인 설명을 위해, 간단한 채팅 어플리케이션을 만들었다. http://simplechat.jang.io/ 에는 방을 선태하고 들어가, 같은 방 사람들과 대화를 나누는 아주 간단한 채팅 기능이 구현되어 있다. 물론 서비스라고 하기에는 부끄러울 정도로 빈약하다. 설명을 위해 급하게 만든 것이니 감안하고 봐 주길 바란다.
2.1. How Does It Use Memory?
여러가지가 있겠지만, 먼저 사용하고 있는 메모리를 확인하는 방법에 대해 알아보자.
Profile It!
가장 생각하기 쉬운 방법은 계속해서 일정 시간 간격으로 메모리 상태를 기록해두고 그것의 추이를 보는 것이다.
https://github.com/wblakecaldwell/profiler

사람들은 생각하는 것이 참 비슷한 것 같다. 당연히 이러한 생각들을 다른 개발자들도 할 것이고, 그래서 누군가가 프로파일링 도구를 만들어 놓았다.
http://simplechat.jang.io/profiler/info.html
profiler에서는 프로세스가 사용하고 있는 전체 메모리,
Heap에 할당된 시스템의 메모리와 Release된 메모리,
Heap 중에서도 실제 allicate되어 사용되고 있는 메모리와 idle 상태의 메모리.
이런 정보를 확인할 수 있다.
What to Watch
자, 그러면 이러한 수치를 통해 어떤 관점으로 봐야 하는지 이야기를 해 보자.
- How much memory does the service use when idle? idle 상태일때 사용하는 메모리는 어느 정도인가? 아무 일을 하고 있지도 않은데 많은 메모리를 사용하고 있다면 점검을 해 보아야 한다.
- How much memory per connection? 하나의 connection이 사용하는 메모리는 어느 정도인가? 이런 정보를 바탕으로, 동시 접속자 몇 명을 수용 할 수 있는지를 알 수 있고, scaling을 조절할 수 있다. 특정 기간동안 이벤트성으로 사용되는 서비스가 있다면, ‘예를들면 광복절을 기념하여 OO 쇼핑몰에서 쿠폰을 쏩니다!!’ 이런 행사를 한다고 했을때, 예측되는 접속자 수에 맞게 서버를 구성하고 그래프의 추이를 보면서 스케일링을 조정할 수 있다.
- Does the system reclaim memory that’s no longer used? 더이상 사용하지 않는 메모리를 잘 회수하고 있는지? (GC)
- What’s the garbage collector doing? GODEBUG=gctrace=1
GC가 일을 제대로 하는지 trace 정보를 통해 확인할 수도 있다.
GODEBUG=gctrace=1환경변수를 셋팅하면 GC 트레이싱이 가능하다. (http://dave.cheney.net/tag/gc) - Where is memory allocated? (PPROF) 좀 더 세부적으로 들어가서, 어떤 고루틴이 얼만큼의 메모리를 사용하고 있는지에 대해서도 궁금할 것이다.
2.2. PPROF
go의 기본 라이브러리인 net의 http 하위 패키지로 net/http/pprof 라는 패키지가 있다.
아주 좋은 도구인데, 의외로 모르는 사람이 많은 것 같다.
PPROF Inspects Your Running Process
pprof는 동작중인 프로세스의 상태를 점검해준다.
- Blocking profile blocking 된 것들은 없는지 확인할 수 있고
- Goroutine count and full stacktraces goroutine의 수와 그것의 stacktrace를 확인할 수 있다
- Heap profile Heap 상태를 프로파일링 해 주고
- Stacktraces that lead to thread creations tread를 생성하는 stacktrace를 확인할 수 있다
Enabling PPROF
사용하는 방법은 아주 간단하다.
import _ "net/http/pprof"를 임포트 하고, 웹서버를 구동시켜놓으면, 확인 가능하다.
참고로 이야기하면 패키지를 임포트할 때, blank identifier로 aliasing을 해서 임포트를 하는 경우가 종종 있다.
가장 많이 볼 수 있는 예는, Go 프로그램에서 database를 사용할때 볼 수 있다.
Go는 database/sql를 통해 데이터베이스 관련 작업에 관련된 추상적인 인터페이스를 제공하고
실제로는 각 DB에 맞는 드라이버 패키지를 임포트해서 사용하도록 한다.
드라이버 패키지는 코드상에서 호출해서 사용하지 않지만, 패키지가 로드될때 호출되는 init() 함수에서 드라이버를 사용하기 위한 작업들을 해 주기 때문에 blank identifier로 ailiasing을 하여 임포트 한다.
net/http/pprof 패키지도 이와같이 blank identifier로 ailiasing을 하여 임포트 한 다음
웹서버를 구동시키면 url로 접근해서 확인할 수 있다.
import (
_ "net/http/pprof"
"net/http"
)
func main() {
http.ListenAndServe(":8080", nil)
// ...
}http://simplechat.jang.io/debug/pprof
PPROF Main Page
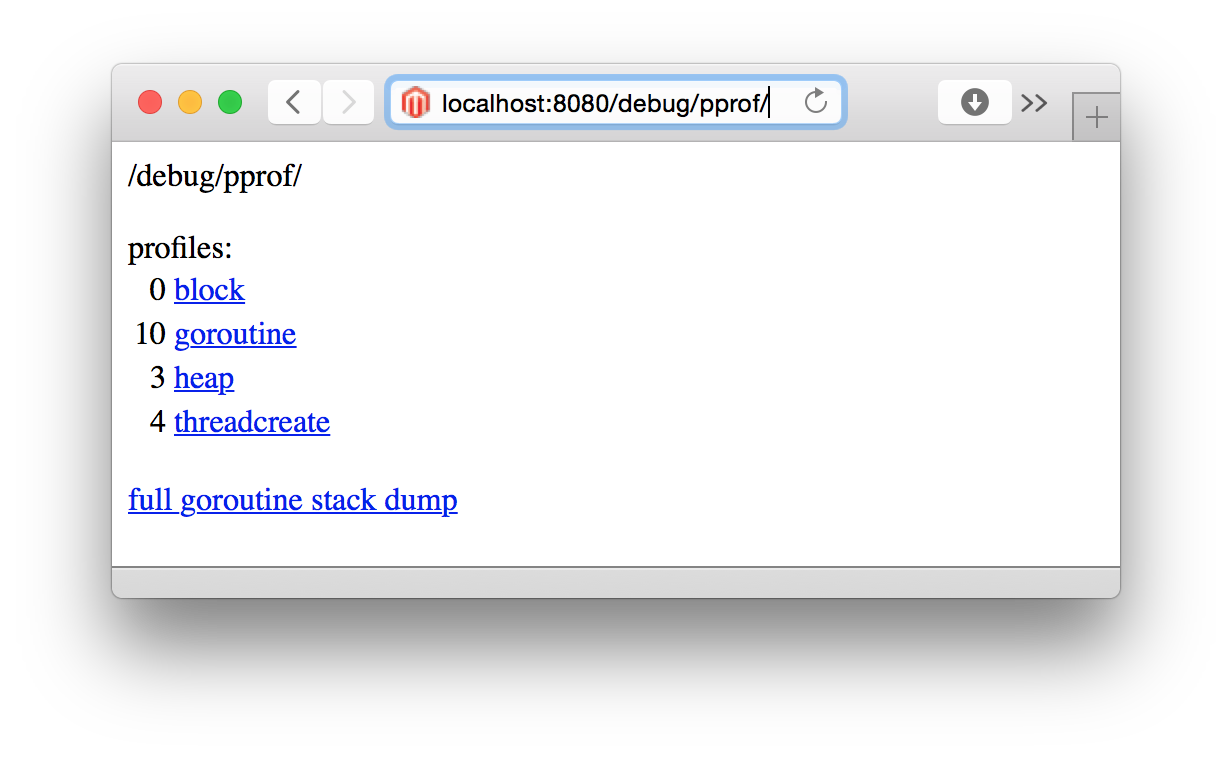
현재 OO개의 goroutine이 있고 O개의 heap과 O개의 thread가 생성되었다.
Don’t leak goroutines!!
쓸데 없는 goroutine이 생기도록 하지 마라
Use PPROF To Tell You:
pprof를 사용하면 이런 것들을 확인할 수 있다.
- How many goroutines when nobody is connected? 아무도 접속하지 않았을때 몇개의 goroutine이 떠 있나?
- How many goroutines per connection? 한 connection당 몇개의 goroutine이 필요하나?
- Are all goroutines cleaned up after all connections close? 모든 connection이 닫히면 모든 goroutine이 clean up 되나?
PPROF: Goroutine Page
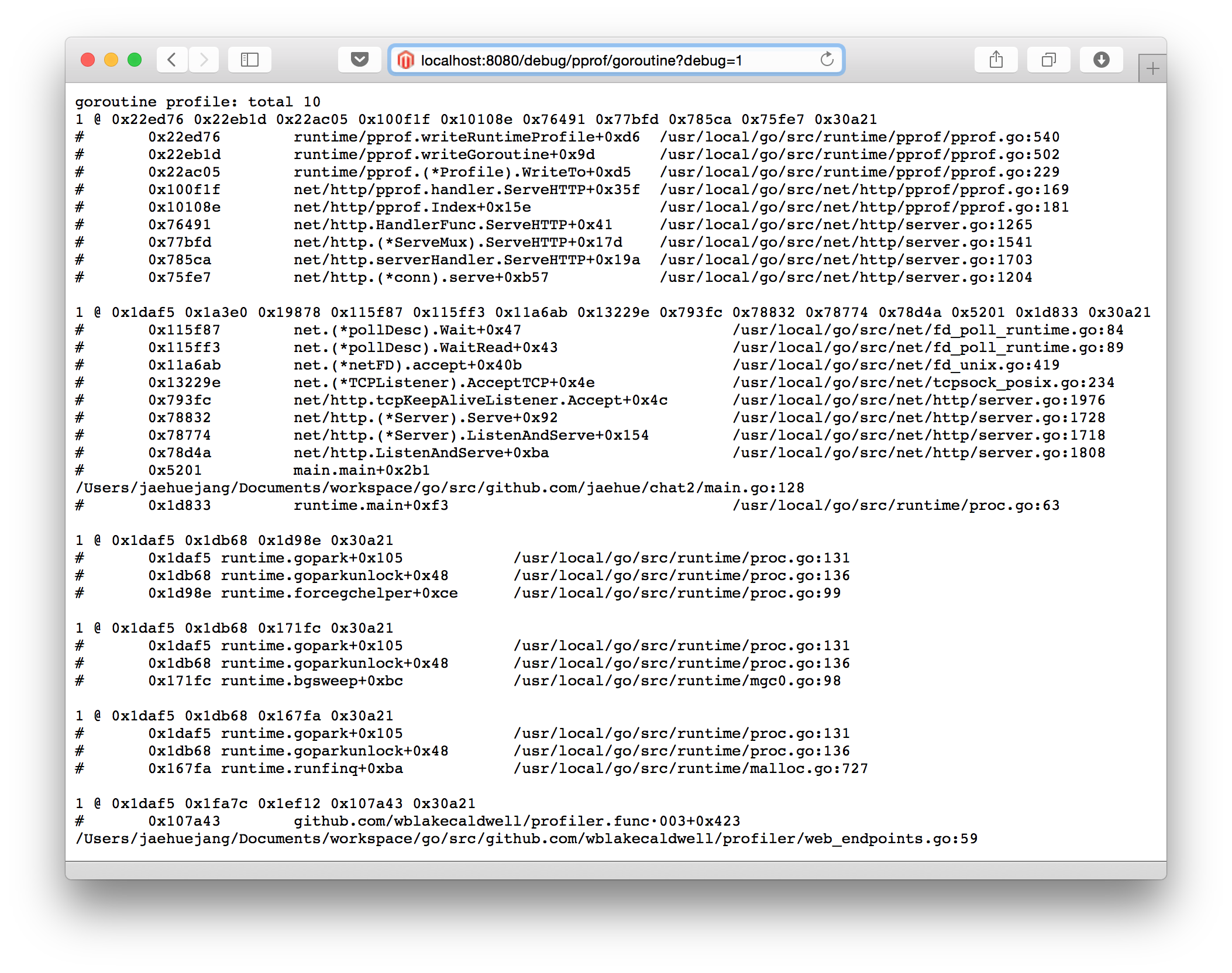
From the Command Line
pprof는 커맨드라인에서도 사용할 수 있다.
What Are Your GoRoutines Doing?
가장 활발하게 일을 하고 있는 상위 10개의 goroutine들이다.
$ go tool pprof ./simple-chat http://simplechat.jang.io/debug/pprof/goroutine
Fetching profile from http://simplechat.jang.io/debug/pprof/goroutine
Saved profile in /Users/jaehuejang/pprof/pprof.simple-chat.simplechat.jang.io.goroutine.002.pb.gz
Entering interactive mode (type "help" for commands)
(pprof) top 10
9 of 9 total ( 100%)
Showing top 10 nodes out of 34 (cum >= 1)
flat flat% sum% cum cum%
7 77.78% 77.78% 7 77.78% runtime.gopark
1 11.11% 88.89% 1 11.11% runtime.notetsleepg
1 11.11% 100% 1 11.11% runtime/pprof.writeRuntimeProfile
0 0% 100% 1 11.11% github.com/wblakecaldwell/profiler.func·001
0 0% 100% 1 11.11% github.com/wblakecaldwell/profiler.func·002
0 0% 100% 1 11.11% github.com/wblakecaldwell/profiler.func·003
0 0% 100% 1 11.11% main.main
0 0% 100% 1 11.11% net.(*TCPListener).AcceptTCP
0 0% 100% 1 11.11% net.(*netFD).accept
0 0% 100% 1 11.11% net.(*pollDesc).Wait
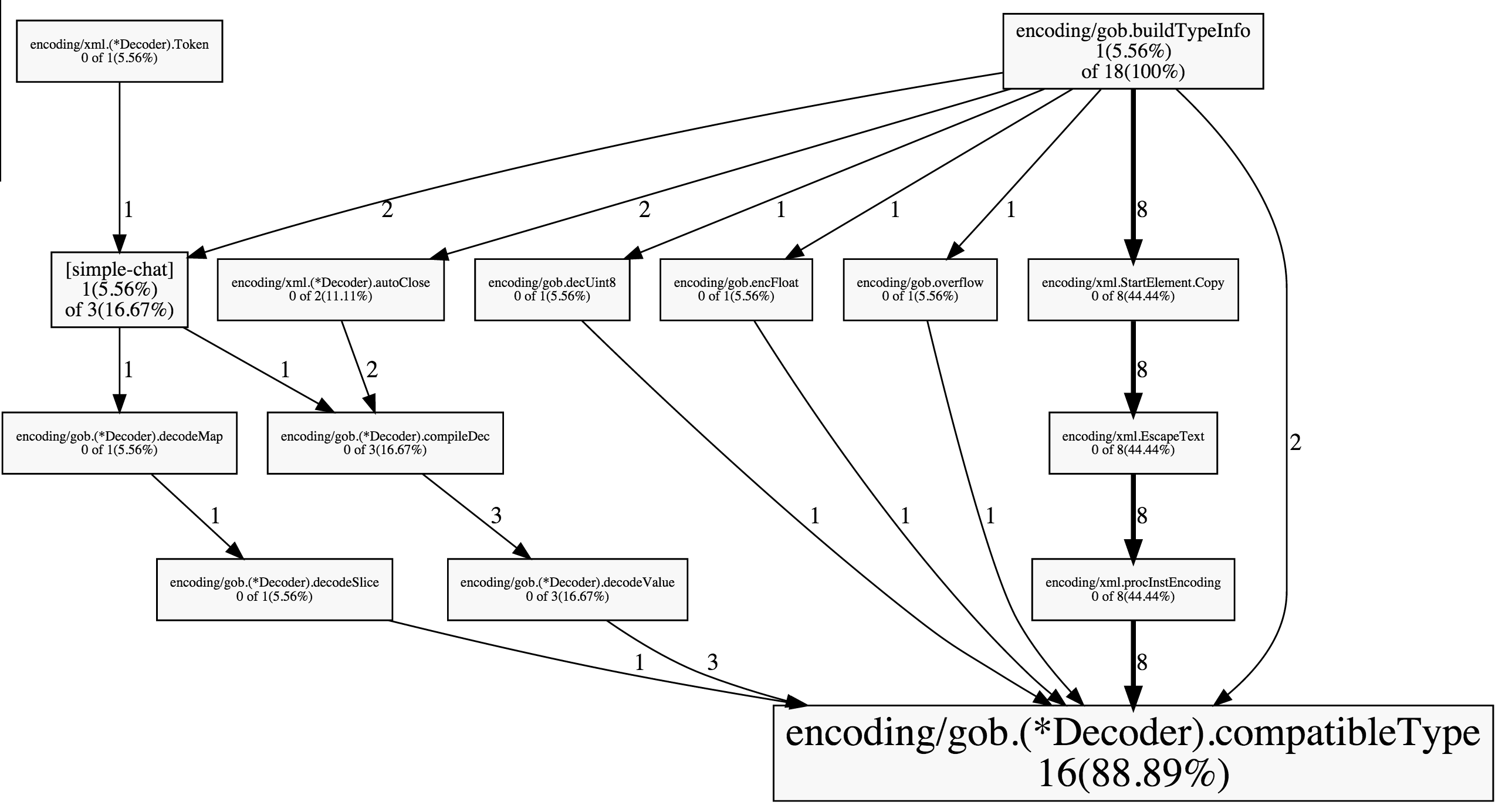
(pprof) webweb 명령은 goroutine간의 연관 관계를 그림으로도 표현해서 svg 파일로 만들어준다.
이 명령이 정상적으로 동작하려면 Graphviz가 설치되어 있어야 한다.
맥 사용자는 $ brew install Graphviz 명령으로 간단하게 설치할 수 있다.
Who’s Allocating Heap Memory?
heap 메모리의 상태도 확인 가능하다.
$ go tool pprof ./simple-chat http://simplechat.jang.io/debug/pprof/heap
Fetching profile from http://simplechat.jang.io/debug/pprof/heap
Saved profile in /Users/jaehuejang/pprof/pprof.simple-chat.simplechat.jang.io.inuse_objects.inuse_space.001.pb.gz
Entering interactive mode (type "help" for commands)
(pprof) top 5
2461.40kB of 2461.40kB total ( 100%)
Dropped 7 nodes (cum <= 12.31kB)
Showing top 5 nodes out of 7 (cum >= 2461.40kB)
flat flat% sum% cum cum%
925.14kB 37.59% 37.59% 925.14kB 37.59% encoding/gob.encComplex64Slice
512.14kB 20.81% 58.39% 512.14kB 20.81% encoding/gob.(*Decoder).compileSingle
512.08kB 20.80% 79.20% 512.08kB 20.80% encoding/gob.encComplex128Slice
512.05kB 20.80% 100% 512.05kB 20.80% encoding/gob.encFloat64Slice
0 0% 100% 2461.40kB 100% [simple-chat]
(pprof) web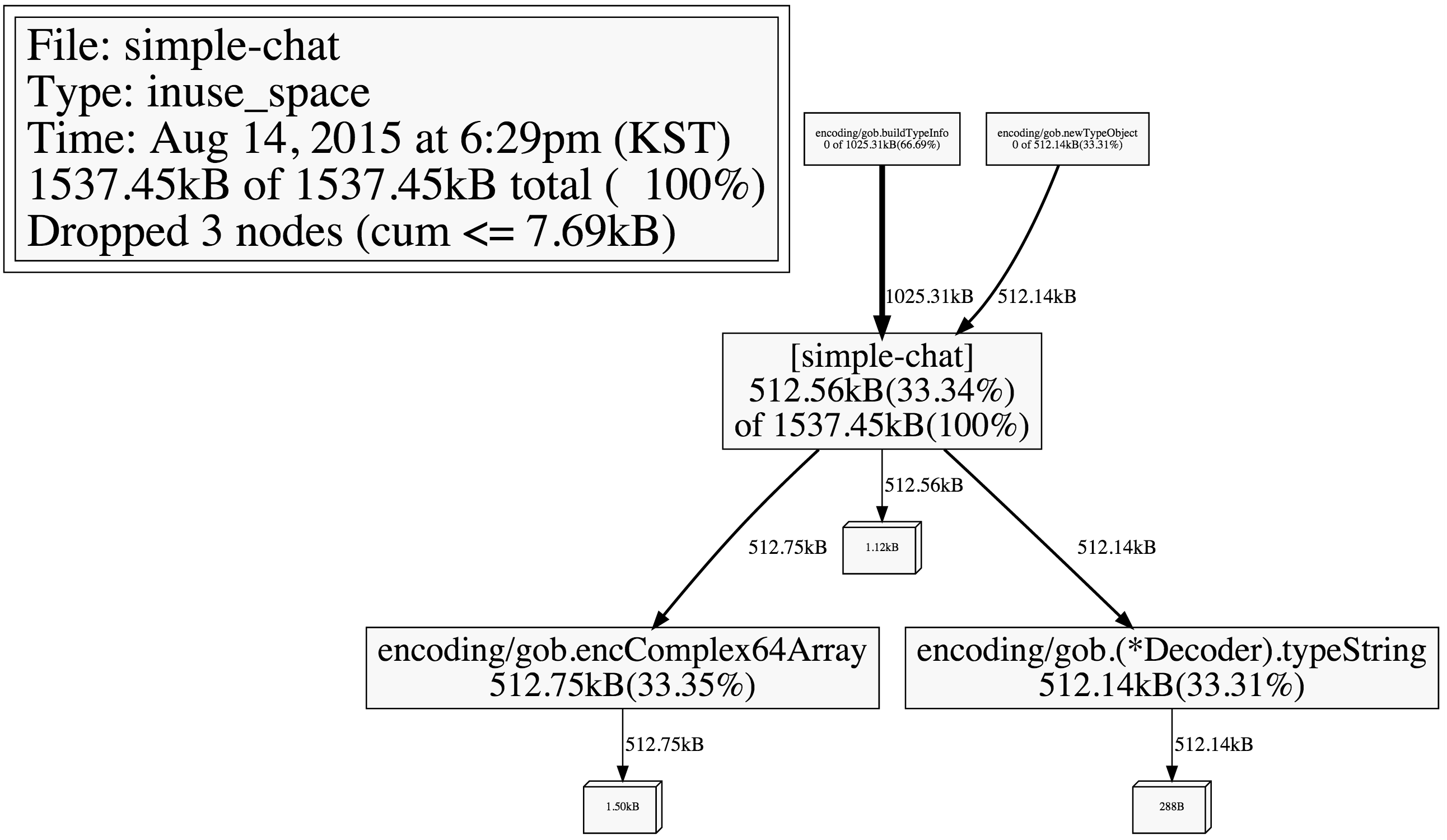
2.3. Watch It Run
이러한 시스템 정보 외에도 추가적인 서비스의 상태를 확인 할 수 있는 기능을 만들어 놓으면 유용하다.
/info Endpoint
예를들면 rest api로 /info 액션을 만들어 현재 서비스의 상태를 확인하도록 만들어놓으면 유용하다.
Version은 몇이고, 이 서비스는 언제 start했고, 현재 시간은 언제이며, 얼마동안 가동되고 있었는지…
서버의 current time은 의외로 유용하다.
Global한 서비스를 운영하고 있는 경우는 필요할때가 있다.
http://simplechat.jang.io/info
Managing Service Version
버전 관리의 팁이 있다.
Version: "1.0.275-b244a2b9b8-20150202.163449"<major>.<minor>.<commit#>-<Git SHA>-<date>.<time>이렇게 버저닝을 하면 편하다.
빌드할때 -ldflags 옵션으로 글로벌 변수의 특정 값을 할당할 수 있는데,
아래와 같이 global variable을 만들어 version을 저장하도록 하고
var ServiceVersion string빌드 할 때마다 ServiceVersion에 빌드 버전이 기록되도록 하면, 빌드시마다 고유의 빌드 버전을 지정할 수 있다.
$ go build -ldflags \
> "-X main.ServiceVersion 1.0.231.fd80bea-20150814.160801"2.4. Keep Good Logs!
사실 정말 필요한 정보는 log만 잘 남겨 놓아도 나중에 유용하게 사용할 수 있다. 하지만 때론 로그가 너무 많아서 보기가 참 힘들어질때가 있다. 로그 파일을 여는데 컴퓨터가 뻗어버리기도 하고, 힘들게 열었는데, 필요한 정보를 찾기도 힘들때도 있다.
그래서 몇가지 팁을 소개한다.
- Create a semi-unique string per request 각 request를 식별할 수 있는 로그 문자열을 만들어라. 여러 request가 동시에 쏟아지는 경우, timestamp만 남기면 하나의 request가 어떤 과정으로 처리되는지 추적하기가 어렵다. heroku에 웹 어플리케이션을 배포하면, 매 요청 정보를 로그로 남기는데, 좋은 예이다. 로그를 보면 각 요청마다 request_id를 할당하고 그것을 함께 로그로 남긴다. 이렇게 하면 여러 request에 대한 로그가 뒤섞여 있어도, 하나의 request가 처리되면서 남기는 로그를 추적할 수 있다.
- Use this request string as a prefix in all log entries log에 의미있는 prefix를 사용해라. 추적하고 싶은 의미 있는 작업에 대해서는 그 의미를 담고 있는 적절한 prefix를 달아주는 것이 좋다.
- Always log at least the start and end of a request 적어도 시작과 끝에는 항상 로그를 남겨라. 실제 로깅 기능을 disable해도 되니까.
로그 레벨을 적절히 사용하여, 개발/스테이징/운영 단계에서 로그 레벨을 조정하며 서비스를 구동시키면 된다.
2.5. Who’s Currently Connected?
더 나아가 지금 누가 접속해있는지가 궁금할 때도 있다.
/connections Endpoint
/connections 액션으로 현재 접속한 유저 정보를 확인하는 기능을 만들어 놓으면 유용하다.
{
CurrentUserCount: 1,
CurrentlyAuthenticatedUsers: [
{
Addr: "10.157.118.9:46493",
Name: "장재휴",
SessionDuration: "3m4s"
}
]
}Conclusion
지금까지 웹서버를 안전하게 작성하는 방법에 대해 소개해봤다. 사실 어려운 내용은 없다. 하지만 놓치기 쉬운 내용들인 것 같다. 이러한 것들을 조금만 신경을 쓴다면, 안전하면서도 관리하기 편리한 서비스를 만들 수 있을 것이다.
댓글
댓글을 불러오는 중...